Originally posted on https://personaelabs.org/posts/efficient-ecdsa-1/
In this post, we introduce our research improving private ECDSA signature verification, stemming from this ETHResearch post and implemented in this repository. We also introduce the importance of client-side proving to unlock the full potential of zero-knowledge cryptography. In a related post we review the pros and cons of not going full-client side: Half server, half client
There will be some math in this post! It might look scary! But the key insights of the method are simple and should teach you some fun cryptography.
Motivation
ECDSA & ring signatures
Digital signatures are a key tool in public-key cryptography, where every user has a public key and private key . In particular, the validity of a digital signature on message generated by can be verified by anyone with access to . As a result, digital signatures allow us to verify the authenticity and integrity of messages or documents. If all messages are attached with a signature from some trusted party, then messages cannot be changed without invalidating the attached signature.
The Elliptic Curve Digital Signature Algorithm, or ECDSA for short, is the signature algorithm used in blockchains like Ethereum and Bitcoin. In particular, each address on these chains is the hash of an ECDSA public key, which itself is a secp256k1 elliptic curve point. And we sign all transactions with our ECDSA public key, which verifies their authenticity and integrity.
Proving you know one of the private keys in a group of public keys without revealing it is a necessary primitive for many of the anonymous speech applications Personae is interested in (heyanon!, storyform, HeyAnoun). Surprisingly, this simple extension requires much heavier cryptographic machinery than a normal signature; there’s an entire field of research dedicated to this problem called ring signatures. Unfortunately these methods aren’t compatible with Ethereum/Bitcoin’s ECDSA keys out of the box, so we opt to use an even more overpowered tool in zkSNARKs.
The zkSNARK method, first implemented by 0xPARC, privately inputs a group member’s public key and a signature , and publicly inputs the entire group (usually succinctly as a Merkle root). The circuit verifies was generated from AND that is in the group . Sounds simple enough!
Unfortunately, the math for the signature verification is very SNARK-unfriendly. In particular, there’s a lot of “wrong field arithmetic” --- the necessary operations happen over the base field of the secp256k1 curve which is different from the scalar field of the curves used in snarkjs. If that means nothing to you, don’t worry — it just means we have a huge blow-up in constraints to make sure all of our elliptic curve math is done correctly. And if that also means nothing to you, don’t worry — it just means computing a proof is very computation and memory-intensive, requiring ~1GB of proof metadata and ~5 minutes of browser computation on a MacBook.
Client-side proving
Okay, so if our gigachad friends at 0xPARC already implemented this method, why don’t we just use that for our applications? Well, a 5 minute proving time that only works on high-end laptops is far from a viable UX. And generating proofs can’t just be offloaded to the cloud — for full privacy it’s necessary these proofs are computed on the user’s device. Otherwise you’ll need to send your plaintext public key to a server to generate your proof, which grants it the power to break your anonymity if it wishes[^1]. There’s some half-server half-client models that have been deployed; we analyze those further here: Half server, half client
But we claim any solution with a server obscures the true unlock of zero-knowledge cryptography. Another framing of the importance of client-side proving is that it allows people to generate authoritative claims of identity without any trusted party, a power us measly humans didn’t have until this technology started to become practical. This means the user can have full custody over their personal data instead of trusting other (potentially misaligned) institutions to manage and verify it.
But the straightforward ZK ECDSA construction is just too expensive for everyone to run on their devices, especially mobile phones. And as more of identity moves on-chain with innovations in DeSoc and SBTs, private ECDSA group membership will be an increasingly important tool in maintaining anonymity and owning more of our identity. And so starting with the ideas in this post, we’ve been on a journey to keep bringing the proving cost down until all devices can easily generate a proof.
Notation
ECDSA signature verification has a bunch of moving parts. All operations are on elliptic curve points and happen modulo , but you can mostly ignore those details for the sake of this post. The main fact you’ll need is that a generator in elliptic curve math is equivalent to “1” in normal math. A more in-depth guide can be found here. Okay, these are each of the variables we’ll need:
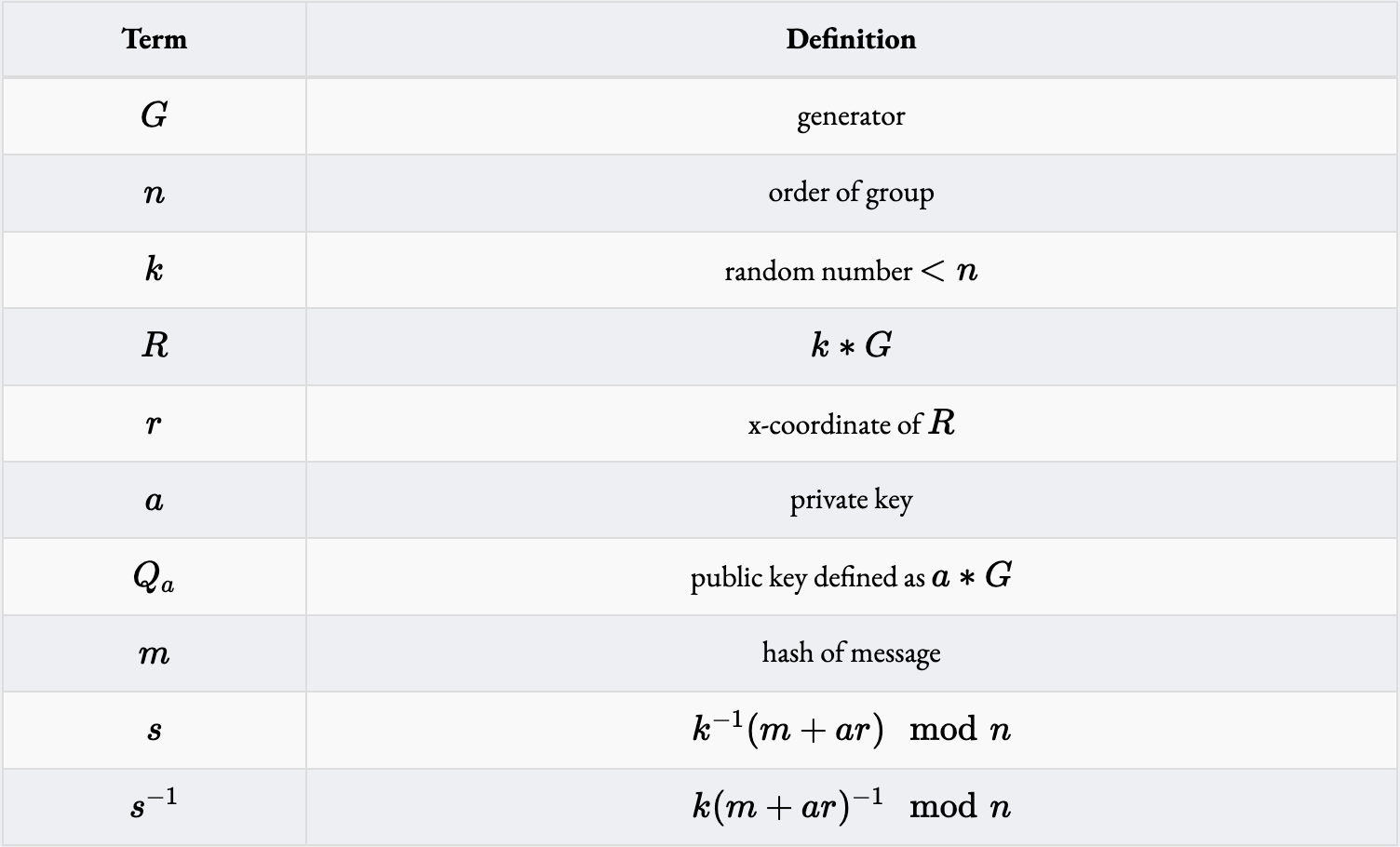
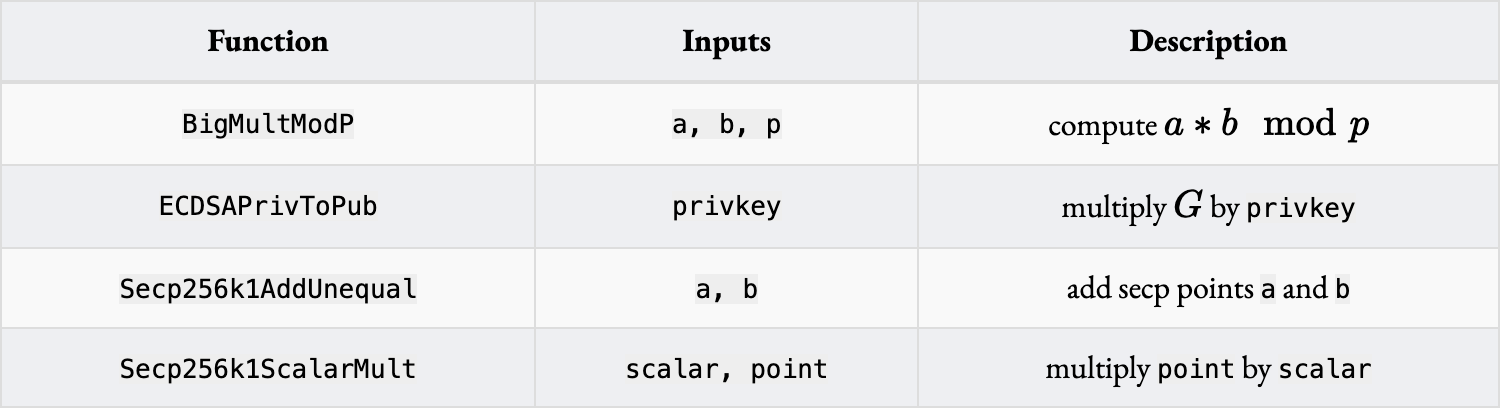
Here are specific circom functions from 0xPARC’s circom-ecdsa that we reference:
An ECDSA signature from public key on the hashed message is the pair . The verification equation[^2] checks if:
which you can follow in 0xPARC’s original implementation. To get better intuition for this signature algorithm, we recommend you check correctness — that is, verify this equation will pass for a valid signature !
If you follow the original code and/or work through the above equation, you’ll see that we need a total of 2 BigMultModP, 1 ECDSAPrivToPub, 1 Secp256k1ScalarMult, and 1 Secp256k1AddUnequal inside of the circuit, for a total of 1,508,136 constraints (the 0xPARC code also inverts but you can pass in so we will ignore it). We want to remove/optimize as many of these functions as possible!
Key insights
Take computation out of the SNARK
Our first insight was that parts of the ECDSA signature verification equation could be taken out of the SNARK without sacrificing privacy. For simplicity we first rewrite the signature verification equation as
If we look carefully at the definition of , we see it is just a random element on the curve. And is publicly known as we are always verifying a signature on a specific message. And so moving , , and outside of the SNARK shouldn’t reveal anything about our user’s public key [^3]. We further rewrite the equation as
From this rewrite, we introduce two new terms:

which we substitute above to get
Because and are defined using , , and , we can compute them outside of the SNARK and pass them in as public inputs. And so with this rewrite we only need to do 1 Secp256k1ScalarMult and 1 Secp256k1AddUnequal inside of the circuit. Okay, 3 operations cut! Is this progress?
Unfortunately, this only cuts 100k constraints from the original 1.5mil constraint circuit, because Secp256k1ScalarMult is by far the most expensive operation. This is implemented as ecdsa_verify_no_precompute in this file for reference. But hope is not lost yet! This rearranged equation is key for our next insight.
Precomputing point multiples
The original 0xPARC code uses a clever optimization to speed up the ECDSAPrivToPub subroutine, which multiples the generator point by a scalar . Because is known in advance, the code stores precomputed multiples of directly in the circuit to reduce the number of operations in ECDSAPrivToPub. The 0xPARC blog post dives into this in more detail.
As is revealed publicly in our rearranged equation, we should be able to do the same technique on to speed up the Secp256k1ScalarMult between and ! However, because changes for every proof, we need to compute these multiples on the fly and pass them in as public inputs. Using the notation of the 0xPARC code, we determined a stride of 8 was most efficient, meaning we compute for all . Precomputing these multiples directly in JS is very slow, so we rewrote the cache computation in Rust and compiled to WASM to majorly reduce the overhead when proving in browser.
This cache of points means we can skip a number of costly operations in normal Secp256k1ScalarMult, bringing our total constraints to 163,239. This is a more than 9x drop from the original circuit! The full method is:
- Public inputs: and precomputed multiples
- Private inputs: ,
- Logic
- Inside zkSNARK circuit
s * T + U = Q_a
- Outside of the zkSNARK - Compute $U$ and precomputed multiples of $T$ in WASM which is implemented as `ecdsa_verify` [here](https://github.com/personaelabs/efficient-zk-ecdsa/blob/8477a39b5a3735724981cd99d19cf36ddb9e8c51/circuits/ecdsa_verify.circom) in circom. ### Off-chain verification Although verifying and storing the proof on Ethereum is good practice in terms of security and convenience, our method makes on-chain verification costly due to number of precomputed multiples we include. Therefore, the proofs from this model must be stored on “cheaper” storage, such as decentralized storage networks (e.g. IPFS, Arweave). From there, clients and servers can verify the proofs on their own, which is an acceptable solution for many non-financial privacy applications. We implement this solution in [heyanoun](https://heyanoun.xyz). The easiest way to make the method on-chain friendly is to reduce the number of precomputed multiples, which decreases the input size but increases the proving time. Another method is to SNARK-ify the "outside of zkSNARK" checks and then link those checks to the original circuit. This requires the original circuit to privately input the precomputed multiples of $T$, but publicly output a hash $h_1$ of all of them. You then have another circuit (which can be computed server-side!) that internally computes the correct multiples of $T$ one by one and also publicly outputs a hash $h2$ of all of them. Then, your verifier or smart contract must input both of these proofs and verify that $h1 == h2$! ### To keccak or not to keccak We also include a version of the circuit called `ecdsa_verify_pubkey_to_eth_addr` that converts the public key to an address using Keccak, which is a total of 315,175 constraints. This is a more than **5x** drop from the old ECDSAVerify + PubkeyToAddress circuit. This circuit is important because many on-chain groups are of addresses not public keys, like airdrop lists. However, if _all_ of the Ethereum addresses in a particular group have sent a transaction (or interacted with a smart contract) at least once, then we can use `ecdsa_verify` instead (which requires meaningfully fewer constraints than `ecdsa_verify_pubkey_to_eth_addr`). This is because we can extract the address's public key from the ECDSA signature of the transaction. ### Credit roll Thank you for making it to the end! Names within each group are sorted alphabetically by first name. - **Project leads**: Dan Tehrani, Vivek Bhupatiraju - **Post writers**: Vivek Bhupatiraju - **Post reviewers**: Aayush Gupta, Amir Bolous, Hadrien Charlanes, Enrico Bottazzi, Lakshman Sankar, Leopold Sayous, Jason Kim, Nikita Kolmogorov, Shrey Jain - **Post inspirations**: David Wong, Dankrad Feist, Vitalik Buterin, halo2 book [^1]: You can technically use _even_ fancier cryptography like [MPC](https://eprint.iacr.org/2021/1530) or [FHE](https://sprl.it/) to avoid sending a plaintext public-key, but these methods are still in development. [^2]: The actual verification only checks that $r$ is equal to the x coordinate of the RHS. This leads to $(r, -s)$ also being a valid signature. However, if the verifier is given $R$ then checking the full equation is equivalent. [^3]: In [deterministic ECDSA](https://datatracker.ietf.org/doc/html/rfc6979#section-3.2), $k$ isn't fully random and is roughly derived from a hash of the user's private key. Revealing $R$ generated deterministically is still secure in our method, which we analyze [here](https://hackmd.io/HQZxucnhSGKT_VfNwB6wOw#Does-R-leak-anything-about-s-and-Q_a).
Reload if nothing is visible.